
Esteja você usando óculos de realidade aumentada (AR) e descansando em uma festa no metaverso ou assistindo a um filme caseiro na sala de estar, o som desempenha um papel importante no aprimoramento da imersão e na criação de uma experiência realista. Para fornecer esses ambientes em Realidade Mista (XR) e Realidade Virtual (VR), a Meta constrói um modelo de inteligência artificial que oferece qualidade de som realista que corresponde ao ambiente real.
Por exemplo, há uma grande diferença entre ouvir um concerto em um lugar grande e na sala de estar. Isso ocorre porque fatores como a estrutura do espaço físico, os materiais e a superfície da estrutura espacial e o local de onde o som é emitido determinam como o som é ouvido.
Pesquisadores do Meta Reality Labs e da Universidade do Texas, em Austin, desenvolveram três novos modelos de inteligência artificial para uma compreensão audiovisual de como a fala humana e o vídeo soam dependendo do ambiente físico do espaço.
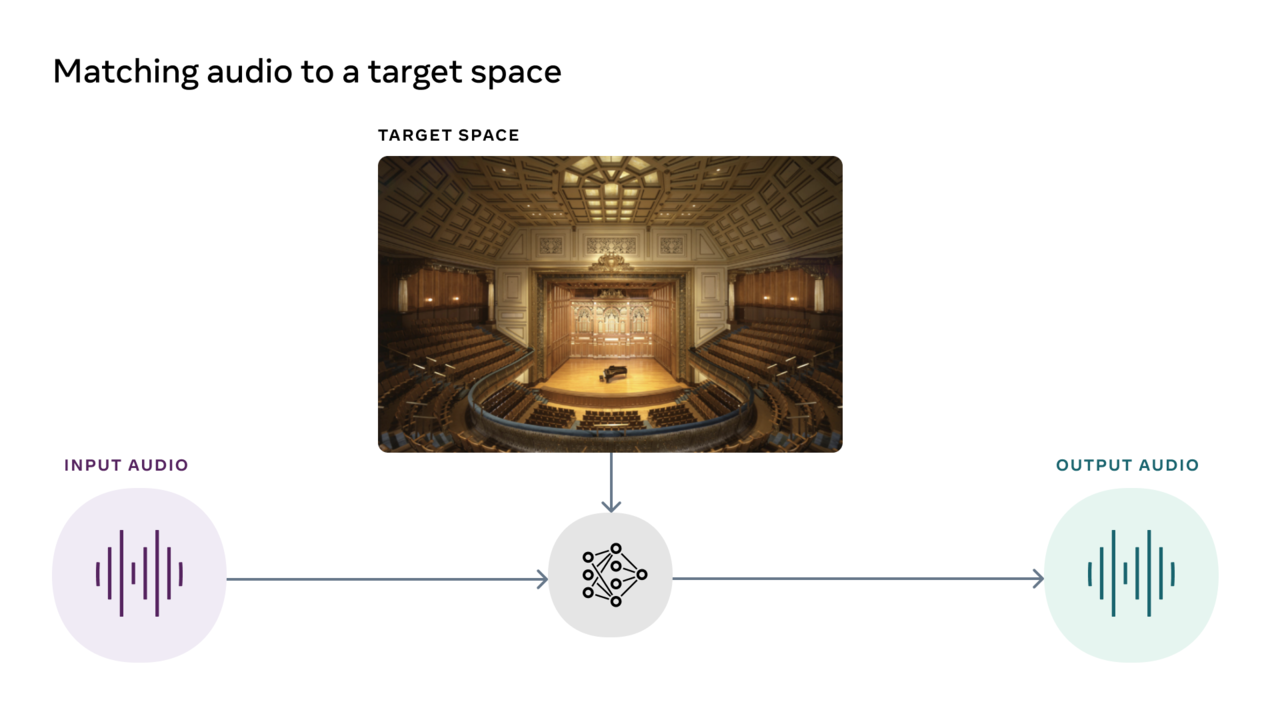
No caso do modelo de correspondência audiovisual, você pode colocar um clipe de áudio gravado como um ambiente de destino e transformar o clipe para que pareça ter sido gravado nesse ambiente. Por exemplo, uma modelo pode tirar uma foto de um restaurante em um restaurante com uma trilha sonora em uma caverna e fazer o som soar como se tivesse sido gravado no restaurante da foto.
O segundo modelo, o modelo de cancelamento de eco informado opticamente, utiliza os sinais sonoros e visuais observados no espaço para cancelar os ecos gerados pelo som de acordo com o ambiente gravado. Este modelo pode extrair um som de violino em uma estação de trem onde uma festa de violino está ocorrendo sem eco reverberando por toda a estação de trem.
O terceiro modelo, VisualVoice, usa pistas visuais e sonoras para separar sons de outros sons de fundo ou sons de fundo. Isso resulta em melhores legendas ou música para festas em VR.
Estudos mostraram que assistir a um vídeo em que o som não condiz com a cena pode causar dor, como tontura. Porque contradiz muito a percepção humana. Mas no passado, combinar áudio e vídeo de diferentes ambientes era um desafio.
O modelo AViTAR desenvolvido pela Meta pode reduzir essa dificuldade. O modelo de correspondência audiovisual adapta o som ao espaço da imagem alvo. Ele usa um modelo de conversor multimídia cujas entradas consistem em imagem e som, permitindo que o transdutor realize inferência multimídia e produza uma saída de áudio realista que corresponda à entrada visual.
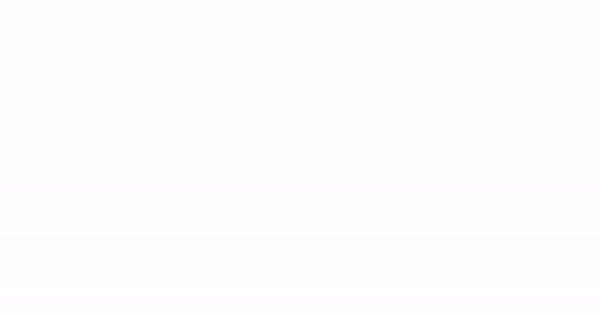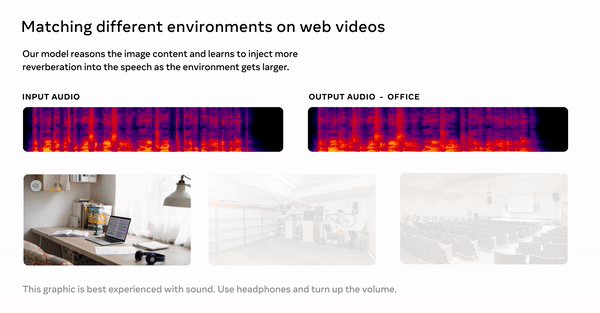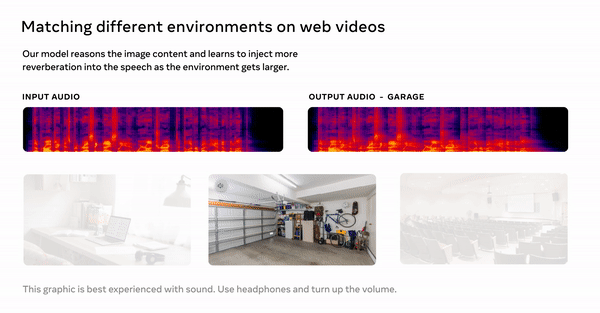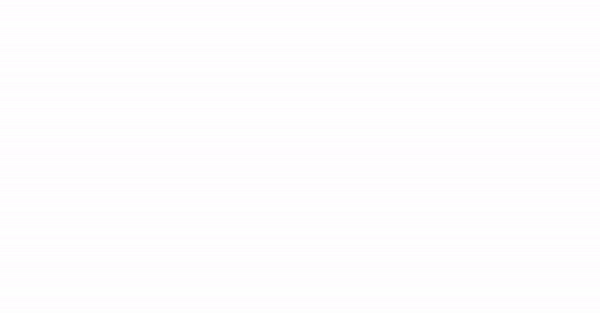
Consiste em clipes de 3 a 10 segundos de pessoas falando do SoundSpace, um conjunto de dados de renderização de áudio criado com simulação realista incorporada de todas as fontes de áudio de conjuntos de dados de Replicação 3D e Matterport de código aberto e 290.000 vídeos em inglês disponíveis publicamente. usado. Ambos os conjuntos de dados se concentraram em sons internos. O microfone e a câmera devem estar longe da fonte de som. Isso foi importante porque o som pode soar diferente dependendo da fonte do som e da localização da pessoa ou do microfone.
Um dos problemas que tiveram que ser superados com o vídeo da web coletado foi ter apenas áudio que combinasse com a acústica do ambiente de destino. Para resolver esse problema, primeiro removemos o eco e depois entrelaçamos o som com a resposta ao impulso de outro ambiente para randomizar o som e adicionar ruído para criar um som com o mesmo conteúdo, mas com um som diferente.
Os modelos foram validados em ambos os conjuntos de dados e a qualidade do som resultante foi medida em três critérios: adequação à realidade, precisão da acústica da sala e qualidade da fala sintetizada. Também pedimos aos ouvintes humanos que avaliassem se o som corresponde a uma imagem de referência, o que resultou no modelo convertendo com sucesso a fala humana em diferentes ambientes do mundo real, conforme mostrado nas imagens.
O caso de uso futuro esperado do modelo de correspondência audiovisual é a recuperação de memórias passadas. Por exemplo, usar óculos de realidade aumentada e visualizar uma imagem 3D da apresentação de balé de seu filho pode reproduzir memórias relevantes. O som remove o eco e cria um som de memória assim como a voz sentada na platéia.

Em alguns casos, adicionar eco com correspondência audiovisual é útil, mas em outras configurações, você precisa fazer o oposto removendo o eco para melhorar a audição e a compreensão. O eco é refletido em superfícies e objetos no ambiente, reduzindo a qualidade da fala perceptível humana e afetando seriamente a precisão do reconhecimento automático de fala. Ao remover o eco, podemos melhorar o reconhecimento de fala com mais facilidade. O reconhecimento automático de fala, por exemplo, ajuda a criar legendas mais precisas para pessoas com deficiência auditiva.
Os métodos anteriores tentaram eliminar o eco com base apenas no método acústico, mas isso não revela o caráter acústico completo do ambiente. O cancelamento de eco cego depende do conhecimento prévio de um idioma sem levar em consideração o ambiente ao redor para o cancelamento de eco. É por isso que a observação visual é tão importante.
O modelo de cancelamento de eco acústico visualmente informado (VIDA) aprende a cancelar reflexões com base em sons visuais e fluxos visuais para influenciar os efeitos de eco audíveis no fluxo de áudio, como estrutura da sala, materiais da estrutura espacial e localização dos alto-falantes. Mostra a referência a um item. Nesse caso, pegamos o som do eco de um local específico e removemos o efeito acústico da sala. Para isso, desenvolvemos um grande conjunto de dados de treinamento usando representações de áudio realistas da fala com base na ação do espaço sonoro.

O terceiro modelo, Visual Voice, compreende a fala observando e ouvindo. Isso é importante para melhorar a percepção humana e da máquina. Uma das razões pelas quais as pessoas são melhores que a IA para entender a fala em ambientes complexos é que usamos nossos olhos e ouvidos. Por exemplo, ao ver a boca de alguém se mover, podemos intuitivamente saber que o som que estamos ouvindo deve vir dessa pessoa. É por isso que estamos desenvolvendo modelos acústico-visuais que, como os humanos, podem reconhecer associações sutis entre visão e audição em conversas.
O VisualVoice aprende dicas visuais e auditivas de vídeo não classificado para obter a separação de fala audiovisual, semelhante à forma como as pessoas adquirem novas habilidades em várias situações. No caso de máquinas, melhor visualização, como fornecer feedback mais preciso. A consciência humana também é melhorada. Por exemplo, no Metaverse, você pode participar de reuniões em grupo com colegas de todo o mundo, conversar com pessoas, conversar entre si, navegar por espaços virtuais e experimentar ecos e acústicas que se ajustam de acordo cada vez que você participa de um grupo menor.
Combinados, esses modelos permitirão que assistentes inteligentes ouçam o que estamos dizendo, seja em shows, festas lotadas ou outros lugares barulhentos.
Os modelos de IA existentes entendem bem as imagens e sua compreensão das imagens está melhorando. Mas construir novas experiências imersivas de AR e VR requer modelos de IA multimídia que possam receber simultaneamente sinais de áudio, vídeo e texto e gerar uma compreensão mais rica do ambiente.
AViTAR e VIDA são atualmente baseados em uma única imagem, mas a definição planeja explorá-la no futuro usando vídeo e outras dinâmicas para capturar as propriedades acústicas do espaço. Isso nos aproxima do nosso objetivo de criar uma inteligência artificial multimídia que entenda o mundo real e como as pessoas o vivenciam.
A Meta projetou um modelo de IA de instalação de áudio para tornar o som mais realista em experiências de realidade virtual e realidade mista. (vídeo = morto)
Membro do AI Times chan park cpark@aitimes.com
[관련기사]Meta lança loja de avatares de luxo
[관련기사]Torne o mundo real mais rico com o metaverso

“Pensador. Aspirante a amante do Twitter. Empreendedor. Fã de comida. Comunicador total. Especialista em café. Evangelista da web. Fanático por viagens. Jogador.”