

Pesquisadores do Instituto de Tecnologia de Massachusetts (MIT) revelaram uma estrutura que pode criar imagens em “tempo real”. É um método que simplifica o processo de múltiplas etapas do modelo de difusão existente em uma única etapa, e a velocidade de geração é considerada a mais rápida entre todas as inteligências artificiais (IA) de geração de imagens.
O MIT News informou no dia 22 (horário local) que pesquisadores do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL) publicaram um artigo sobre “destilação conformada de distribuição (DMD)”, que simplifica o processo de várias etapas do modelo de difusão em um único etapa. Publicado no arquivo onlineEle disse que fez isso.
Os geradores de imagens de IA normalmente funcionam por meio de um processo chamado “difusão”. Essencialmente, o modelo que gera a imagem começa com um estado confuso, desfocado e ruidoso e depois refina a imagem através de sucessivas etapas de amostragem até que fique nítida e realista. Como tal, a propagação é geralmente um processo demorado que requer muitas etapas.
No entanto, os pesquisadores do MIT usaram uma nova abordagem chamada DMD, que reduziu drasticamente o processo de criação de 30 a 50 etapas para uma única etapa.
Isso também reduziu a carga de computação. Enquanto o “Stable Diffusion 1.5” leva cerca de 1,5 segundos para criar uma imagem em hardware moderno, o novo modelo baseado em DMD do MIT leva apenas cerca de 1/500 de segundo.
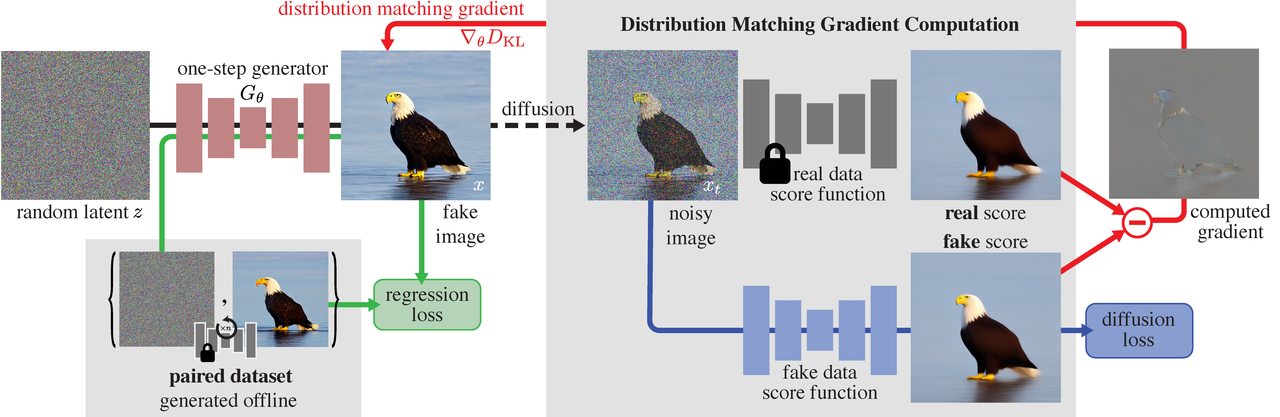
Embora hardware mais rápido produza velocidades mais rápidas, a velocidade da modelagem baseada em DMD não se deve a hardware poderoso, mas sim à tecnologia que gera conteúdo visual em uma única etapa, combinando os princípios de redes adversárias generativas (GAN) e modelos de difusão. GAN é um modelo generativo que aprende duas redes diferentes em conflito e gera dados semelhantes aos reais.
A aceleração de modelos generativos de IA muitas vezes envolve um compromisso entre qualidade e velocidade. No entanto, em modelos baseados em DMD, tais compensações raramente existem e fornecem resultados de geração muito mais rápidos, mantendo a qualidade da imagem.
O DMD aproveita o modelo de difusão, que cria imagens de alta qualidade usando um processo iterativo, e o GAN, que gera imagens rapidamente. Em outras palavras, este DMD combina a excelente qualidade da amostra de um modelo de difusão com a velocidade inerente de um GAN.
O DMD aprende com o conhecimento dos modelos de difusão existentes, gera imagens mais semelhantes e melhora o realismo da saída ao distinguir entre imagens reais e geradas. A explicação é que com isso é possível manter alta precisão e capacidade de melhoria iterativa ao mesmo tempo em que utiliza o pré-aprendizado do modelo de difusão e o procedimento de amostragem rápida.
“Nosso trabalho é um novo método que acelera os modelos de difusão existentes, como a difusão em estado estacionário e o DALLE-3, por um fator de 30”, enfatizaram os pesquisadores.
“Isso não apenas reduz significativamente o tempo de computação, mas também mantém a qualidade do conteúdo visual gerado. Este é potencialmente um novo método de modelagem generativa com velocidade e qualidade superiores”, disse ele.
Esta não é a primeira vez que pesquisadores descobrem como realizar a difusão em muito menos etapas para acelerar o processo de criação de imagens.
A Stability AI lançou um modelo chamado Stable Diffusion XL Turbo, que pode criar imagens de 1 megapixel reduzindo o processo de criação de 50 etapas a uma única etapa de difusão.
O Stable Diffusion XL Turbo funciona de maneira muito semelhante à abordagem “DMD” do MIT. A GPU NVIDIA A100 pode gerar uma imagem de 512 x 512 em apenas 207 milissegundos, o que representa uma melhoria significativa na velocidade em relação aos modelos anteriores de difusão de IA.
Repórter Park Chan cpark@aitimes.com

“Leitor implacável. Especialista em mídia social. Amante de cerveja. Fanático por comida. Defensor de zumbis. Aficionado por bacon. Praticante da web.”