

Esteja você em uma festa no Metaverso ou usando óculos de realidade aumentada (AR) e assistindo a um filme caseiro na sala de estar, o áudio desempenha um papel importante na experiência desses momentos. Estamos trabalhando em experiências de realidade virtual e mista como esta e acreditamos que a inteligência artificial (IA) será a chave para fornecer uma qualidade de som que corresponda de forma realista às configurações nas quais as pessoas estão imersas.

Assim, a equipe de pesquisa da Meta AI, especialistas em áudio do Meta Reality Labs e a equipe de pesquisa liderada pela professora Kristin Grumman, da Universidade do Texas, no Departamento de Ciência da Computação e Engenharia de Austin, lideraram a pesquisa. A fonte abriu três novos modelos de IA para compreensão audiovisual da fala humana e sons de vídeo.

Este modelo foi projetado para nos levar da realidade virtual para a realidade em um ritmo mais rápido.
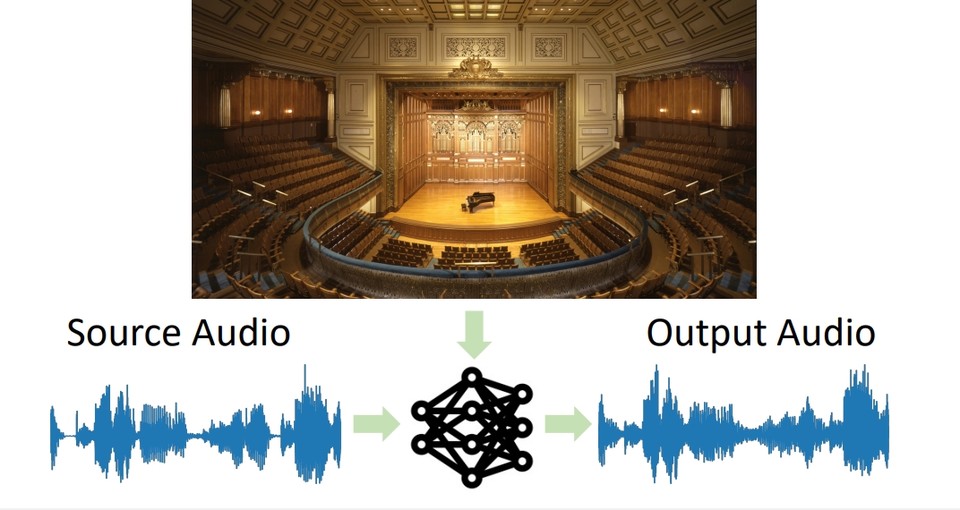
O modelo da equipe de pesquisa é baseado na compreensão do ambiente físico de uma pessoa com base em sua aparência e voz. Por exemplo, há uma grande diferença entre fazer um concerto em um grande teatro e fazê-lo na sala de estar. A razão é que a geometria do espaço físico, os materiais e superfícies na área e a proximidade da fonte sonora são todos fatores que foram colocados na maneira como ouvimos o som.

O modelo que a equipe de pesquisa compartilha com a comunidade de IA concentra-se em três tarefas audiovisuais que superam os métodos tradicionais.
Em primeiro lugar, a correspondência audiovisualpapel) ‘, você pode inserir um clipe de áudio gravado em qualquer lugar com a imagem do ambiente de destino e converter o clipe em áudio como se tivesse sido gravado naquele ambiente (abaixo está uma apresentação oral de 5 minutos no CVPR 2022).
Por exemplo, a modelo pode tirar uma foto de um restaurante em um restaurante com o som de um som gravado em uma caverna e, em vez disso, ter aquela voz soando como se tivesse sido gravada no restaurante na foto.
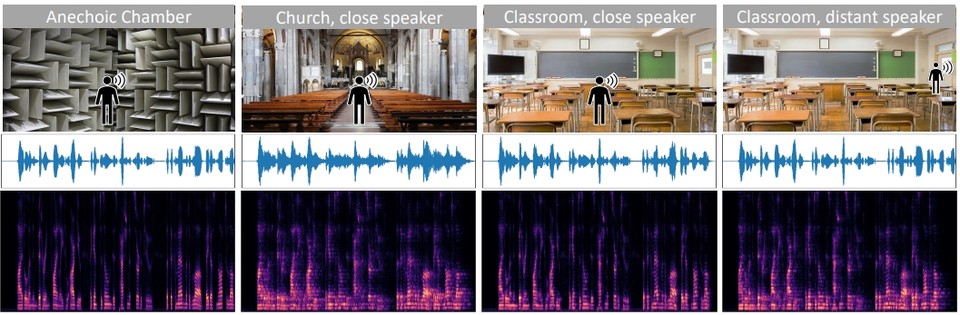
O segundo modelo, “Remoção de falhas ópticas-papel)’ focado no cancelamento de eco (echo), que é o eco que o som faz de acordo com o ambiente gravado, usando as pistas visuais do som e do espaço observados em oposição à correspondência acústico-visual (menos do que o ambiente simulado e o mundo real ). Imagem audiovisual da fala com eco reduzido e eco em todos)
Terceira Forma VisualVoice-papel/o apoio/cifra) aprende pistas visuais e auditivas de vídeo não classificado para alcançar a separação de fala audiovisual, semelhante à forma como as pessoas adquirem novas habilidades em várias situações.
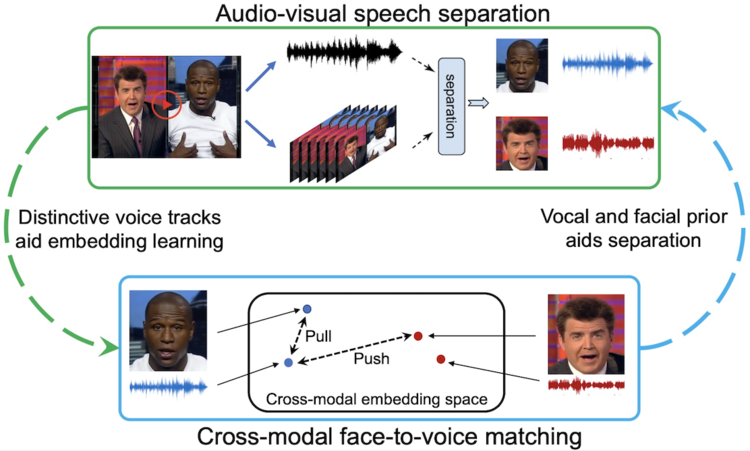
Ou seja, ele usa pistas visuais e de áudio para separar a fala dos sons de fundo e outras falas (abaixo está uma apresentação audiovisual da correspondência visual e de áudio dos dados sintéticos e do vídeo da web)
No Metaverse, por exemplo, você pode participar de reuniões de grupo com colegas de todo o mundo, mas o eco e o som se adaptam conforme as pessoas se movem e se juntam ao espaço virtual, em vez de falar menos e conversar umas com as outras.
Todas as três tarefas acima estão relacionadas à área geral de pesquisa de IA que a Meta AI faz em relação ao reconhecimento audiovisual. O objetivo é criar um futuro onde as pessoas possam usar óculos de realidade aumentada e se sentirem imersas em som e gráficos ao recriar uma memória 3D que se pareça exatamente com o que estão experimentando de sua perspectiva, ou quando jogam no ambiente virtual (abaixo ). é um vídeo introdutório de síntese de áudio baseada em IA para realidade aumentada e virtual)

“Leitor implacável. Especialista em mídia social. Amante de cerveja. Fanático por comida. Defensor de zumbis. Aficionado por bacon. Praticante da web.”