
Foi desenvolvida uma nova arquitetura de aprendizado profundo que reduz o número de neurônios ativados para inferência em redes neurais. Com isso, foi revelado que a velocidade de inferência e o custo dos grandes modelos de linguagem (LLM) foram reduzidos em até 300 vezes.
VentureBeat anunciou no dia 24 (horário local) que pesquisadores da ETH Zurich desenvolveram uma arquitetura “Fast Feed Forward” que reduz a carga computacional ao identificar neurônios de inferência adequados na camada feed-forward da rede neural do transformador, que é a base do LLM , e anunciou que foi publicado.
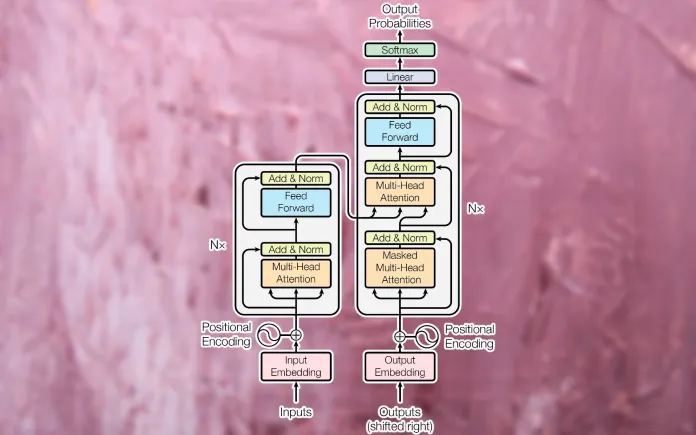
Em geral, o modelo transformador, que rastreia o contexto e o significado aprendendo dados sequenciais, como palavras em uma frase, consiste em uma camada de “atenção” que entende o significado de elementos de dados discretos e uma camada feed-forward responsável por transformar os dados de entrada. . Fazer.
Em particular, a camada feed-forward é uma parte computacionalmente intensiva que deve calcular a saída de todos os neurônios e parâmetros de entrada, que é a chave para o desempenho do modelo.
Os pesquisadores apresentaram uma nova arquitetura fast-feed-forward (FFF), tendo em mente que nem todos os neurônios da camada feed-forward precisam estar ativos durante o processo de inferência da entrada.
FFF usa uma operação matemática chamada “multiplicação de matrizes condicionais (CMM)”, que substitui a “multiplicação de matrizes densas (DMM)” usada nas atuais redes feed-forward.
DMM é um processo computacionalmente intensivo e ineficiente que multiplica todos os parâmetros de entrada por todos os neurônios da rede. Por outro lado, um CMM processa inferência usando um pequeno número de neurônios, organizando-os em uma árvore binária e executando condicionalmente apenas um ramo, dependendo da entrada. Em outras palavras, o FFF pode fazer com que os modelos de linguagem funcionem de forma rápida e eficiente, identificando os neurônios apropriados para cada computação e reduzindo significativamente a carga computacional.
Para verificar esta técnica, os pesquisadores desenvolveram um modelo “Fast BERT”, que substituiu a camada feed-forward baseada em transformador do “BERT” do Google por FFF.
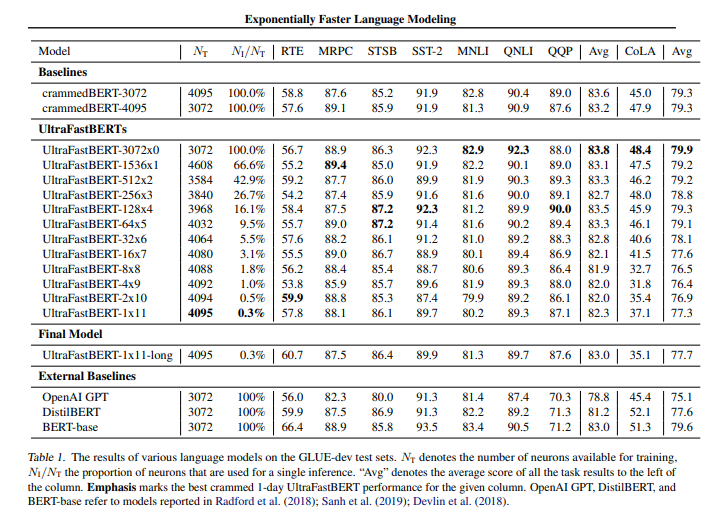
O modelo Fast Butt foi otimizado em várias tarefas no benchmark General Language Understanding Evaluation (GLUE) e mostrou desempenho semelhante ao modelo Butt existente de tamanho e procedimento de treinamento semelhantes.
O modelo Fast Butt treinado por apenas um dia em pelo menos uma GPU A6000 manteve 96% do desempenho do modelo Butt, e nos melhores resultados experimentais alcançou o mesmo desempenho do modelo Butt tradicional usando apenas 0,3% dos neurônios em a camada feedforward.Frente, aparentemente.
Em particular, os pesquisadores disseram que a integração da rede FFF no LLM tem potencial para uma enorme aceleração. Por exemplo, no GPT-3, a rede feed-forward de cada switch consiste em 49.152 neurônios, mas se for substituída por uma rede FFF profunda de 15 camadas, terá um total de 65.536 neurônios, mas para inferência real, GPT- 3 is Apenas 16 neurônios foram usados, ou cerca de 0,03% dos neurônios.
Como resultado, com a introdução da arquitetura FFF, o hardware e o software do DMM usado na rede neural feed-forward existente podem ser melhorados.
Além disso, os resultados mostram que a velocidade de inferência é melhorada em 78 vezes em comparação ao DMM por CMM aplicado à rede FFF. Se implementada usando hardware melhor e algoritmos de baixo nível, a velocidade de inferência tem potencial para melhorar em mais de 300 vezes, explicaram os pesquisadores.
“Esta pesquisa resolverá gargalos de memória e computação no LLM e abrirá caminho para um modelo de linguagem mais simples e eficiente”, disseram os pesquisadores.
Como tal, pesquisas recentes sobre LLM concentram-se na redução de custos e tempo, melhorando a eficiência.
Na semana passada, pesquisadores da Universidade de Stanford e da UC Berkeley revelaram “S-LoRA”, uma técnica de ajuste fino LLM que permite que centenas ou milhares de modelos sejam executados em uma única GPU.
O modelo de linguagem leve ‘Orca 2’ (sLLM) anunciado pela Microsoft (MS) na semana passada também tem apenas 7 bilhões e 13 bilhões de parâmetros, mas mostra capacidade de inferência superior ao modelo de linguagem maior (LLM) e tem vantagens.
Repórter Park Chan cpark@aitimes.com

“Leitor implacável. Especialista em mídia social. Amante de cerveja. Fanático por comida. Defensor de zumbis. Aficionado por bacon. Praticante da web.”