
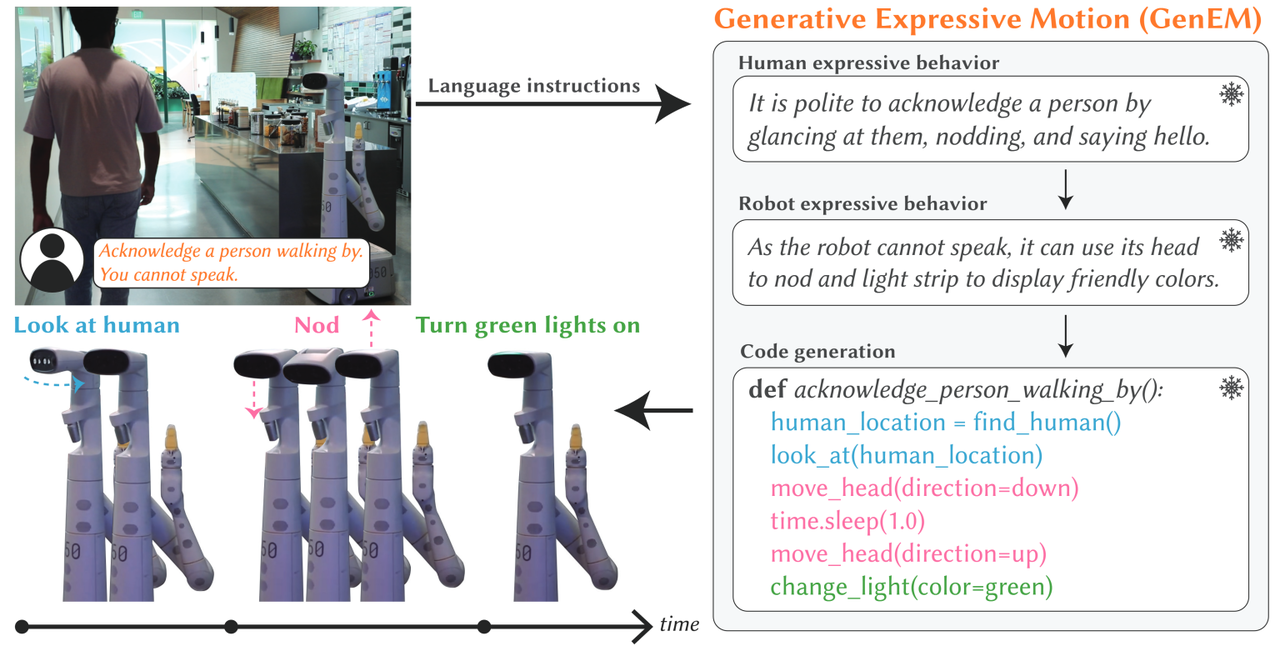
Surgiu uma solução que permite aos robôs gerar diferentes comportamentos ou gestos expressivos, como balançar a cabeça para mostrar compreensão ou balançar a cabeça de um lado para o outro para expressar desaprovação.
VentureBeat anunciou no dia 6 (horário local) que pesquisadores do Google DeepMind, da Universidade de Toronto e da empresa de robótica Hoku Labs usaram um grande modelo linguístico (LLM). “GenEM”, uma solução que cria diferentes gestos para robôsFoi relatado que foi tornado público.
Assim, o GenEM utiliza o rico conhecimento incorporado no LLM para gerar dinamicamente o comportamento expressivo do robô. Por exemplo, um LLM pode ditar que é educado fazer contato visual ao cumprimentar alguém ou acenar com a cabeça para reconhecer a presença ou comando da pessoa.
“A chave é aproveitar o rico contexto social disponível no LLM para gerar um comportamento expressivo adaptativo e configurável”, disseram os pesquisadores.
GenEM usa uma série de “agentes de IA” para gerar automaticamente o comportamento expressivo de um robô a partir de comandos de linguagem natural. Cada agente infere o contexto social associado a um comando de linguagem natural e invoca a API do robô apropriada para o comportamento expressivo desejado.
O pipeline GenEM começa com comandos de linguagem natural. A entrada pode ser uma expressão simples, como “Acene com a cabeça”, ou pode descrever um contexto social no qual as normas devem ser seguidas, como “Quando alguém cumprimentá-lo, acene com a cabeça para trás”.
Na primeira etapa, o LLM utiliza uma técnica motivacional chamada “cadeia de pensamento” para explicar passo a passo como um ser humano reagiria em uma determinada situação.
Em seguida, outro agente de IA aplica movimentos emocionais humanos ao robô, passo a passo. Por exemplo, você pode direcioná-lo para acenar usando as funções de rotação e inclinação da cabeça ou imitar um sorriso exibindo padrões de luz pré-programados na tela frontal.
Finalmente, outro agente mapeia a ação de atuação gestual do robô em código executável baseado em comandos da Interface de Programação de Aplicativo (API). Isso permite que o GenEM atualize os gestos gerados.
Os pesquisadores explicaram especificamente que nenhuma dessas etapas requer treinamento LLM e que dependem de engenharia rápida que só precisa ser adaptada à funcionalidade do robô e às especificações da API.

Usando o GPT-4 da OpenAI, testamos como os gestos gerados aparecem para os humanos. Uma pesquisa foi realizada com dezenas de pessoas que compararam o aplicativo ▲GenEM com feedback do usuário, o aplicativo ▲GenEM sem feedback e o aplicativo ▲Gesture projetado por um animador profissional.
Como resultado, a maioria sentiu que as animações criadas pela ZenEM eram tão fáceis de entender quanto aquelas cuidadosamente escritas por animadores profissionais. Os pesquisadores também descobriram que a abordagem de várias etapas usada no GenEM era muito melhor do que usar um único LLM para traduzir diretamente no movimento do robô.
Devido à sua arquitetura baseada em hot-routing, o GenEM enfatizou que o mais importante é que ele funcione em qualquer tipo de robô sem a necessidade de treinar o modelo em um conjunto de dados especial. Além disso, ele demonstrou que expressões complexas podem ser realizadas combinando movimentos simples de robôs.
“Nossa abordagem fornece uma estrutura flexível para gerar comportamentos expressivos flexíveis e combináveis por meio de recursos LLM”, concluíram os pesquisadores.
Repórter Park Chan cpark@aitimes.com

“Pensador. Aspirante a amante do Twitter. Empreendedor. Fã de comida. Comunicador total. Especialista em café. Evangelista da web. Fanático por viagens. Jogador.”